
概要
データベースの歴史を振り返るに、リレーショナルデータベース (RDBMS) が占める位置は大きいです。1969年に誕生したRDBMSは、後に導入されたDDLであるSQL言語とともに、コンピューターの歴史を大きく変えました。テーブルに対して"関係演算"を行うことでデータを処理するというアイディアは、現実世界のデータ構造とよくマッチしていたと言えるでしょう。
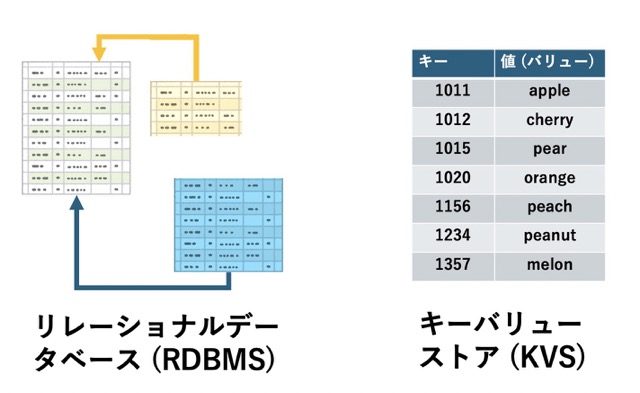
しかし、RDBMSが普及しすぎたことで逆に、「RDBMSが苦手とする部類のデータを管理する」需要が掘り起こされました。その結果、NoSQLと総称される、全く新しいデータベースのカテゴリが生まれました。有名なものとしては、例えば次のようなものがあります。
| NoSQL | 説明 | ソフトウェアの例 |
|---|---|---|
| キーバリューストア (KVS) | 「キーに対する値」といった単純なデータ構造の管理 | Redis、memcached、DynamoDB |
| ドキュメント志向 DB | XMLやJSONなどの構造データの管理 |
MongoDB、CouchDB、Cassandra |
| グラフ志向 DB | ツリー構造など、グラフ上に連なったデータの管理 | Neo4j、ArangoDB、OrientDB |
このうち、代表的なキーバリューストアの1つであるRedisについて、今回は詳しく解説していきます。
Redisとは
Redisは2009年に誕生した、"オープンソース" のKVSです。その性能から多くの企業で利用され、高速なデータベースとして貢献してきました。Redisが持つ特長について、いくつかまとめてみましょう。
1. インメモリデータベースで高速
`RDBMS`が生まれた時代は、現代のように膨大な量のメモリを利用できなかったため、記録されるデータはディスク上に保存されていました。そのため、アクセスする際にディスクの読み込みが発生し、パフォーマンスの低下を招いていました。
しかしRedisはインメモリデータベース……つまりメモリ上にデータを保持すること前提の設計なので、ディスク経由より遥かに高速な処理を行えます。ことインターネット時代において、大量のアクセスを捌けることは大きな利点と言えるでしょう。
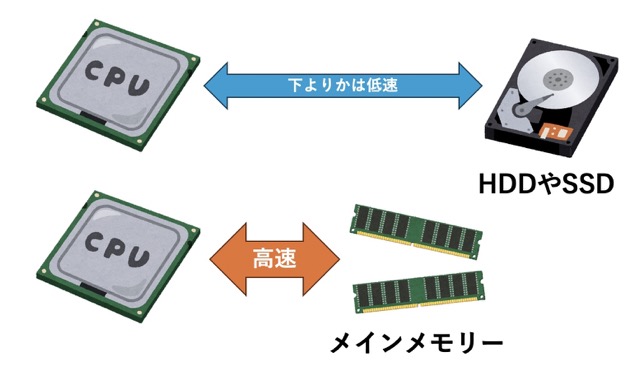
ただ、その利点を裏返せば、「そこまで多くのデータを載せられない」「電源が切れるとデータが消えてしまう」という欠点となります。ゆえにRedisは、一時的なデータを保存しておくための「データキャッシュ」として使われることが多いです。
補足:Redisは非同期的に、保持しているデータ内容をディスクに書き込みます。そのため、インメモリデータベースでありながら、電源を切ってもデータを保持するような芸当も可能です。
2. 多様なデータ構造に対応している
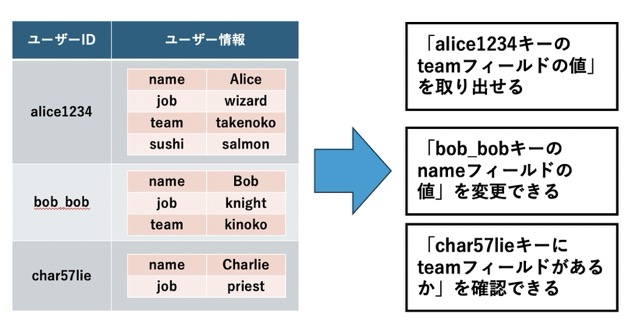
KVSにおいて「キー」は概ね文字列ですが、「値 (バリュー)」は文字列とは限りません。例えば、上記の例で上げたmemcachedは、キーに対応する値として、(文字列を含む) 単純なバイナリデータを格納することができます。
ここでRedisの場合、単なる文字列 (バイナリ) だけでなく、リスト構造・セット構造・ハッシュテーブルなど、より複雑なデータをバリューとして格納できます。例えば「ユーザーID」キーに対して「ユーザーに対応した設定項目」をバリューとするようなことができるのです。
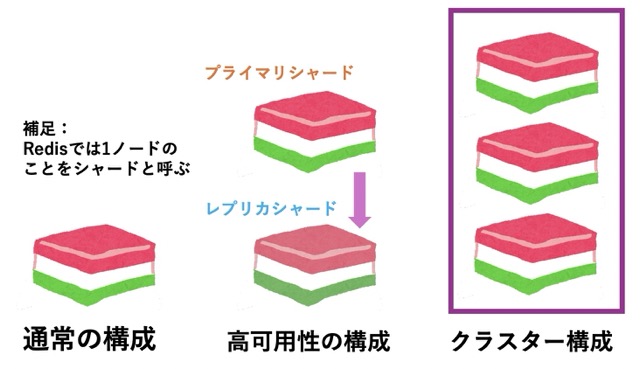
3. 分散処理でスケールアウト可能
Redisは単独でも大量のリクエストを捌けますが、複数のRedisを協調動作させる「Redis Cluster」を構成できます。これにより、保持するデータを分散させて読み書きパフォーマンスを維持したり (シャーディング)、クラスターを構成するサーバーがダウンしても、他のサーバーがその役割を引き継ぐことができます (レプリケーション)。
4. 便利な関連ツール
JSONデータをバリューとして保存して活用する際に役立つRedisJSON- インデックス検索や全文検索を行うための
RediSearch
など、Redisには様々な関連ツールが提供されています。今回の記事では解説しませんが、Redisを利用する際は検討の余地ありかと。
Redisの操作方法
Redisについて説明したところで、具体的な使い方について解説します。まず、実験用の環境構築にはDockerを使用します。幸い、公式リポジトリがありますので、起動はすんなり行えるでしょう。
# Redisの最新版 (redis:latest) を、ポート番号 6379 で起動
docker run --name my-redis -p 6379:6379 -d redis
次に、当該Redisサーバーに接続し、各種操作を行います。
1. Dockerコンテナ内に存在するRedis CLIを使う場合
# Dockerコンテナ内に入場
docker exec -it my-redis bash
# Redis CLIを起動。以降、ターミナル上での表記が「127.0.0.1:6379> 」と入力待ち状態になる
redis-cli
すると、入力待ち状態になりますので、データを入れたり取り出したりしてみます。
# 文字列をセット、文字列を取り出す
SET mykey "Hello, Redis!" # 指定したキーに指定したバリューをセット。すでにキーが存在する場合は上書き
GET mykey # 指定したキーに対応するバリューを取得。ここでは「"Hello, Redis!"」と表示される
SETNX mykey "Bye, Redis!" # SETと違い、既にキーが存在する場合は何もしない
MSET key1 "value1" key2 "value2" # 複数のキーに対して複数のバリューをセット
MGET key1 key2 # 複数のキーの値を取得。例えば「1) "value1" 2) "value2"」と表示される
# リストをセット、リストを取り出す
RPUSH mylist "item1" "item2" "item3" # リストの末尾にアイテムを追加。リストが無ければ新規作成
LPUSH mylist "item0" "itemA" "itemB" # リストの先頭にアイテムを追加。リストが無ければ新規作成
LRANGE mylist 0 -1 # リスト内のアイテムについて、インデックス0から全て表示される
LRANGE mylist 0 1 # リスト内のアイテムについて、インデックス0から1まで表示される
LRANGE mylist 2 2 # リスト内のアイテムについて、インデックス2のみ表示される
LINDEX mylist 3 # リスト内の指定したインデックスのアイテムを取得
LPOP mylist # リストの先頭からアイテムを取り出す。元のリストからは削除される
RPOP mylist # リストの末尾からアイテムを取り出す。元のリストからは削除される
# ハッシュテーブルにセット、ハッシュテーブルからデータを取り出す
HSET myhash field1 "value1" # ハッシュテーブルにフィールドと値をセット
HGET myhash field1 # ハッシュテーブルから指定したフィールドの値を取得。無い場合はnilが返る
HGETALL myhash # ハッシュテーブル内の全てのフィールドと値を取得
HDEL myhash field1 # ハッシュテーブルから指定したフィールドを削除
HKEYS myhash # ハッシュテーブル内の全てのフィールドを取得
HVALS myhash # ハッシュテーブル内の全ての値を取得
# その他
DEL mykey # 指定したキーを削除
EXISTS mykey # 指定したキーが存在するか確認
KEYS my* # 「my」で始まるキーを表示。「KEYS *」にすると全てのキーが表示される
FLUSHALL # 全てのキーを削除
2. Python用のライブラリを使う場合
もちろん各種言語向けにライブラリは存在しますが、例としてPythonを使用して操作してみます。操作内容は「1. Dockerコンテナ内に存在するRedis CLIを使う場合」で行った操作と同じです。「どの接続先サーバーに接続するか」は、Redisサーバーのそれ……今回の場合はlocalhost:6379に接続します。
import redis
# Redisは1インスタンスにつき、デフォルトで16個の論理データベースを管理している
# 「db=0」は、そのうちの0番目のデータベース (db=0はデフォルト値) に接続することを意味する
r = redis.Redis(host='localhost', port=6379, db=0)
# 文字列についての操作
r.set('mykey', 'Hello, Redis!')
print(r.get('mykey'))
r.setnx('mykey', 'Bye, Redis!')
r.mset({'key1': 'value1', 'key2': 'value2'})
print(r.mget(['key1', 'key2']))
# リストについての操作
r.rpush('mylist', 'item1', 'item2', 'item3')
r.lpush('mylist', 'item0', 'itemA', 'itemB')
print(r.lrange('mylist', 0, -1))
print(r.lrange('mylist', 0, 1))
print(r.lrange('mylist', 2, 2))
print(r.lindex('mylist', 3))
print(r.lpop('mylist'))
print(r.rpop('mylist'))
# ハッシュテーブルについての操作
r.hset('myhash', 'field1', 'value1')
print(r.hget('myhash', 'field1'))
print(r.hgetall('myhash'))
r.hdel('myhash', 'field1')
print(r.hkeys('myhash'))
print(r.hvals('myhash'))
# その他の操作
r.delete('mykey')
print(r.exists('mykey'))
print(r.keys('my*'))
r.flushall()
Amazon MemoryDB for Redisの操作方法
前述したように、Redisは自分でサーバーを立てて利用することができます。ただ、クラウドサービスにおけるマネジメントサービスとして提供されることもあります。例えば Amazon MemoryDB for Redis や Memorystore for Redis や Azure Cache for Redis など……。
その中で、例えばAmazon MemoryDB for Redisについて触ってみましょう。AWS のコンソールからAmazon MemoryDBのページに移動し、Redisクラスターを作成します。

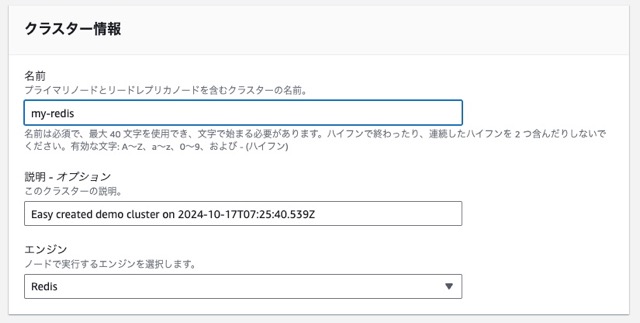
その後、クラスターに付けた名前を控えつつ、次のように冒頭のコードを修正します。
from redis.cluster import RedisCluster
import boto3
CLUSTER_NAME = 'my-redis'
memorydb = boto3.client('memorydb')
cluster_info = memorydb.describe_clusters(ClusterName=CLUSTER_NAME)
endpoint = cluster_info['Clusters'][0]['ClusterEndpoint']['Address']
port = cluster_info['Clusters'][0]['ClusterEndpoint']['Port']
r = RedisCluster(
host=endpoint,
port=port,
ssl=True,
)
# 以下略
まとめ
簡単にキーバリューストア (KVS) やRedisの歴史について触れた後、Redis CLIやPythonから触る際の使い方について解説しました。
おまけ:Redisの「オープンソース」について
記事の冒頭で「"オープンソース"」と引用符付きで表記しました。これは、厳密なところの「オープンソース」……つまり完全に利用が自由な状態ではなくなっていることを意味します。
Redis社の公式ブログ記事や公式解説ページによると、もともとは3条項BSDライセンスで配布していたRedisについて、RSALv2ライセンスとSSPLv1ライセンスのデュアルライセンスに変更したとのこと。2つライセンスの内容を要約するとこんな感じ。
- (この場合は
Redisについて) ソフトウェアを商用化し、またはマネージドサービスとして他者に提供する行為 - ライセンス、著作権、その他の通知を削除または不明瞭にする行為
つまり、ソースコード自体は読めたとしても、その利用方法を制限する……例えばAmazon MemoryDB for Redisのようなサービスを提供する際にライセンス契約を結ばせたいということですね。
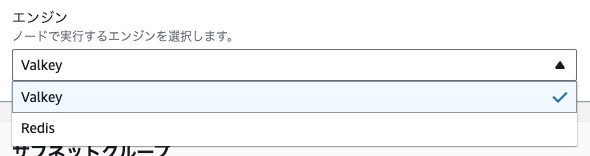
じゃあ現行のAmazon MemoryDB for Redisなどはどうするのかって話ですが、上記のような「ライセンス変更をする前のバージョンの Redis」、もしくは「ライセンス変更前の Redis をフォークしたもの」については新ライセンスが適用されないと見られており、AWS などは後者のデータベース (Valkey) を採用するとのこと。
実のところ、Amazon MemoryDBでクラスターを作成する際も、エンジンにRedisだけでなくValkeyも選択肢として表示されるようになっています。AWSとしては「今後こちらを使ってね (互換性はあるので問題ないよね)」ということなのでしょう。
- 閲覧数 464








コメントを追加