
----------------------------------------
Elasticsearchは、オープソースの高スケーラブルな全文検索および分析エンジンです。
大容量のデータをすばやく、ほぼリアルタイムで保存、検索、分析できます。
通常、検索の機能と要件が複雑なアプリケーションを強化する基礎となるエンジン/技術として使用されます。
----------------------------------------
(公式ドキュメントより引用)
上記説明にもあるように、Elasticsearchはデータベースの一種です。ただ、リレーショナルデータベースと違い、テーブル定義を決めずとも、データを出し入れすることができます(NoSQL)。また全文検索エンジンを利用できるので、大量の文章に対して分析を掛けることもできます。
ところで、ElasticsearchにはREST APIからアクセスすることができます。つまり、JavaScriptから叩いて利用することができるはずです。そこで、Elasticsearchにアクセスすることを通じ、「書籍についての情報を登録・検索するWebアプリ」を作成してみます。
※説明の都合上、Webフロントエンド開発には、TypeScript+React+Bootstrap4を使うものとします
Elasticsearchの環境構築Dockerを利用するのが手っ取り早いでしょう。公式ドキュメントによると、https://www.docker.elastic.coからDockerイメージをpullしろとありますので、現在(2020/04/24)時点で最新のものをpullしておきます。
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.6.2
また、日本語による全文検索エンジンを使用したいので、analysis-kuromojiをコンテナ作成時にインストールしておくことにします。Docker利用の場合、Dockerfileにインストールコマンドを記述しておくと良いでしょう。
FROM docker.elastic.co/elasticsearch/elasticsearch:7.6.2
RUN elasticsearch-plugin install analysis-kuromoji
その上で、Docker-composeにより、環境を構築します。公式ドキュメントの記述を参考に、Dockerfileと同じディレクトリに、docker-compose.ymlを記述します。
- 公式ドキュメントのものとの差異:
- コンテナ作成時の設定を、DockerイメージそのままではなくDockerfile由来にした
- デフォルトではCORSの問題があるので、外部オリジンからのアクセスを許可した
- 「
version: '2.2'」を「version: '3'」にした
version: '3'
services:
es01:
build: .
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- http.cors.allow-origin=*
- http.cors.enabled=true
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
build: .
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- http.cors.allow-origin=*
- http.cors.enabled=true
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data02:/usr/share/elasticsearch/data
networks:
- elastic
es03:
build: .
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- http.cors.allow-origin=*
- http.cors.enabled=true
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
後は、コンテナをビルドして起動することで、Elasticsearch側の設定は完了です。
docker-compose build
docker-compose up -d
データ構造
書籍データについてですが、次のような情報を参照するものとします。
interface Book {
id: string;
title: string; // 書名
author: string; // 著者
editor?: string; // 編集者(著者=編集者の場合は不要)
drawer?: string; // 作画(著者=作画の場合は不要)
translator?: string; // 翻訳者(いない場合は不要)
publisher: string; // 出版社(同人誌の場合はサークル名)
summary: string; // 概要
url: string; // URL(販売元など)
}
ここで重要なのは、editorとdrawerが、TypeScriptにおける「string | undefined」型だということです。つまり定義されていないことがあります。
リレーショナルデータベースの場合は、undefinedであることを表現するため、NULL許容にするか、空文字列を入れていたところでした。しかしElasticsearchの場合、そのことを「単にそのキーの値が入っていない」ということで表現できます(詳しくは後述します)。
表示用のフォームを作成
ReactなのでFunctional Componentを構築することになります。
import React from 'react';
// サンプル書籍データ
const SAMPLE_BOOK_LIST: Book[] = [
{ id: '1', title: 'こころ', author: '夏目漱石', publisher: '集英社',
summary: '教科書では第三部のみ収録されがちな、夏目漱石の代表作。\n「わたし」と「先生」との交流、そして「先生」の告白を描く。',
url: 'https://www.aozora.gr.jp/cards/000148/card773.html' },
{ id: '2', title: '走れメロス', author: '太宰治', publisher: '筑摩書房',
summary: '著者の自堕落な実体験が元ネタらしい、太宰治の代表作。\n愛と誠の力を、いまこそ知らせてやるがよい。',
url: 'https://www.aozora.gr.jp/cards/000035/card1567.html' },
{ id: '3', title: 'あなうさピーターのはなし', author: 'Potter, Beatrix',
drawer: 'Potter, Beatrix', translator: '大久保 ゆう', publisher: '(不明)',
summary: 'おとうさんがパイにされたことで有名な、ピーターラビットシリーズの一作。\n調べるまで、まさか青空文庫に収録されているとは思っていませんでした。',
url: 'https://www.aozora.gr.jp/cards/001505/card51344.html' },
];
// 表示する書籍データのテーブルレコード
const BookTableRecord: React.FC<{book: Book}> = ({book}) => {
let bookAuthor = book.author;
if (book.editor !== undefined || book.drawer !== undefined || book.translator !== undefined) {
bookAuthor = `著:${book.author}`;
if (book.editor !== undefined) {
bookAuthor += `\n編:${book.editor}`;
}
if (book.drawer !== undefined) {
bookAuthor += `\n作画:${book.drawer}`;
}
if (book.translator !== undefined) {
bookAuthor += `\n翻訳:${book.translator}`;
}
}
return <tr>
<td className="align-middle"><a href={book.url} target="_blank" rel="noopener noreferrer">{book.title}</a></td>
<td className="align-middle"><pre className="text-left mb-0">{bookAuthor}</pre></td>
<td className="align-middle">{book.publisher}</td>
<td className="align-middle"><pre className="text-left mb-0">{book.summary}</pre></td>
</tr>;
};
// 全体表示
const App: React.FC = () => {
return (
<div className="container">
<div className="row my-3">
<div className="col text-center">
<h1>書籍DB</h1>
</div>
</div>
<div className="row my-3">
<div className="col text-center">
<table className="table table-condensed table-bordered">
<thead>
<tr>
<th>書名</th>
<th>著者</th>
<th>出版社</th>
<th>概要</th>
</tr>
</thead>
<tbody>
{SAMPLE_BOOK_LIST.map((book) => <BookTableRecord key={book.id} book={book} />)}
</tbody>
</table>
</div>
</div>
</div>
);
}
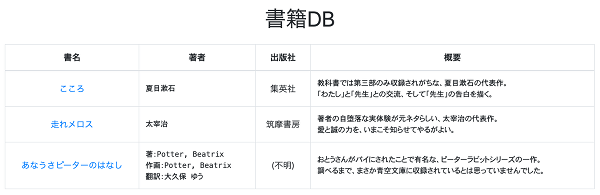
ここまでで、次の画像のように、一覧が表示できるようになりました。著者列については、入力値によって変化させるように工夫しています。
データの投入処理
実装に入る前に、リレーショナルデータベースとElasticsearchにおける用語の違いについて整理しましょう。
| RDB | Elasticsearch |
|---|---|
| データベース | Cluster |
| テーブル | Index |
| レコード | Document |
| カラム | Fields |
| プライマリーキー (任意の型が0個以上) | Document ID (文字列型が1個) |
また、Elasticsearchの場合、リレーショナルデータベースと違い、次のような差異があります。
- データ挿入時、IDを指定しなくても挿入可能(RDBのAUTO_INCREMENTに相当)。自動挿入されるIDは連番の整数ではなく、ランダムな文字列となる
- Fieldsにおける各キーは、Document毎に一定でなくてもいい
- Indexをあらかじめ作成していなくても、いきなり任意の名称のIndexに挿入可能。事前にIndexを作成することもできる
それを踏まえた上で、次のcurlコマンドとSQL文をご覧ください。どちらも、「インデックスbook_indexのID=1に対してレコードを挿入する」処理を実行しています。
# curlコマンド(Elasticsearch)
curl -X PUT "http://localhost:9200/book_index/_doc/1" -H 'Content-Type: application/json' -d'
{
"title": "銀河鉄道の夜",
"author": "宮沢賢治",
"publisher": "筑摩書房"
}
'
# SQLコマンド(リレーショナルデータベース)
INSERT INTO book_index (id, title, author, publisher) VALUES (1, '銀河鉄道の夜', '宮沢賢治', '筑摩書房');
こういった動きをTypeScriptで実装すると、例えばこんな感じになります(フォーム側の実装は割愛)。
// 送信メソッド
const postDocument = async (book: Book) => {
// 送信用データを準備する
const data: { [key: string]: any } = {};
data['title'] = book.title;
data['author'] = book.author;
data['publisher'] = book.publisher;
data['summary'] = book.summary;
data['url'] = book.url;
if (book.editor !== '') {
data['editor'] = book.editor;
}
if (book.drawer !== '') {
data['drawer'] = book.drawer;
}
if (book.translator !== '') {
data['translator'] = book.translator;
}
// 送信処理(ID未指定なのでPOSTでないと駄目)
const temp = await fetch(`${SERVER_URL}/book_index/_doc/`, {
mode: 'cors',
method: 'POST',
body: JSON.stringify(data),
headers: {
'Content-Type': 'application/json'
}
});
if (temp.ok) {
window.alert('追加しました。');
} else {
window.alert('追加できませんでした.');
}
};
データの検索処理
こちらもREST APIで実行できます。戻り値はJSONなので、hits.hitsキーにアクセスすれば、検索結果が得られます。ただし、Elasticsearchの場合、デフォルトでは検索結果の先頭10件だけを返します。全件取得したい場合は、次の記事が参考になるでしょう。
# curlコマンド(Elasticsearch)
curl -X GET "localhost:9200/book_index/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match_all": {} }
}
'
# SQLコマンド(リレーショナルデータベース)
SELECT * FROM book_index AS A ORDER BY A._score DESC LIMIT 10;
// curlコマンドの戻り値(レスポンスボディ)
{
"took": 320,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "book_index",
"_type": "_doc",
"_id": "Wll1unEBOqfY_dggX89b",
"_score": 1,
"_source": {
"title": "銀河鉄道の夜",
"author": "宮沢賢治",
"publisher": "筑摩書房",
"summary": "ジョバンニが銀河鉄道を通じ、生きる意味を知る宮沢賢治の名作。\n映画で擬人化した猫になったのは有名だが、原作では普通の人間である。",
"url": "https://www.aozora.gr.jp/cards/000081/card43737.html"
}
}
]
}
}
今回の案件について、データの取得コードをTypeScriptで実装すると、こんな感じになります。sizeパラメーターで取得件数を増やせるので、とりあえず大きめの値を指定しています(真面目にscrollさせる処理を実装するのは大変なので)。なおGETではなくPOSTを投げているのは、TypeScript(JavaScript)の仕様上、GETにリクエストボディを含ませることができないからです。
const getDocuments = async (): Promise<Book[]> => {
const temp = await fetch(`${SERVER_URL}/book_index/_search`, {
mode: 'cors',
method: 'POST',
body: JSON.stringify({"query": { "match_all": {} }, "size": 100,}),
headers: {
'Content-Type': 'application/json'
}
});
if (temp.ok) {
const response = await temp.json();
return response['hits']['hits'].map((record: any) => record['_source'] as Book);
} else {
return [];
}
};
全文検索エンジンを使用する
検索時の設定としては、キーワード指定や範囲指定など、多様なオプションが存在します。詳しくは公式ドキュメントのこのページを読むといいでしょう。
Request Body Search | Elasticsearch Reference
これを使うと、簡単に全文検索させることができます。
curl -X GET "localhost:9200/book_index/_search" -H 'Content-Type: application/json' -d'
{
"query": { "match": {"summary": "映画"} }, "size": 1
}
' | jq
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 672 100 610 100 62 3674 373 --:--:-- --:--:-- --:--:-- 4048
{
"took": 126,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
// 中略
}
クライアントに実装するとすると、例えばこんな感じになるでしょう。
const getDocuments = async (keyword: string): Promise<Book[]> => {
let requestBody: any = { "query": { "match_all": {} }, "size": 100, };
if (keyword !== '') {
requestBody = { "query": { "match": {"summary": keyword} }, "size": 100, };
}
const temp = await fetch(`${SERVER_URL}/book_index/_search`, {
mode: 'cors',
method: 'POST',
body: JSON.stringify(requestBody),
headers: {
'Content-Type': 'application/json'
}
});
if (temp.ok) {
const response = await temp.json();
return response['hits']['hits'].map((record: any) => record['_source'] as Book);
} else {
return [];
}
};
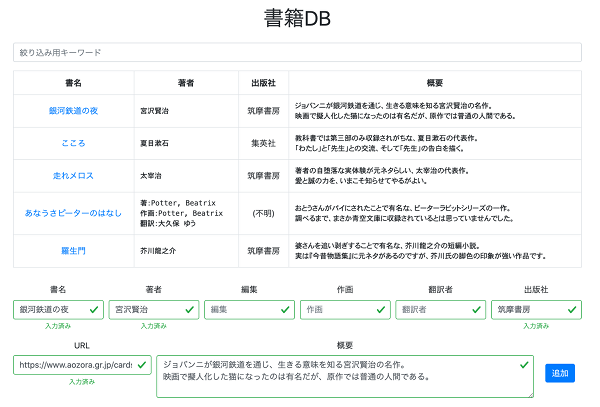
例によってフォームの追加実装は端折りますが、最終的に次のようなアプリが完成しました。
- 閲覧数 1811


コメントを追加