AWS bedrockを試してみる
AWS bedrockのワークショップの内容をもとににbedrockを試してみたので紹介します。
今回は主にテキスト生成に焦点をあてて説明します。
bedrockとは
bedrockはAWSが提供する生成AIのサービスとなります。
Amazonが提供する基盤モデルだけではなく、大手企業(Meta,Anthropic,Stablity AI)のFMを使用することができます。
bedrockを利用できるリージョンが限られる為注意が必要となります。
この記事ではバージニア北部リージョンを使用する前提で記載しますが、東京リージョンでも利用可能となります。
モデルのリクエスト
最初にbedrockを使用する場合はモデルのリクエストを行う必要があります。
モデルのリクエストはAWSコンソール > bedrock > モデルアクセス から行うことができます。
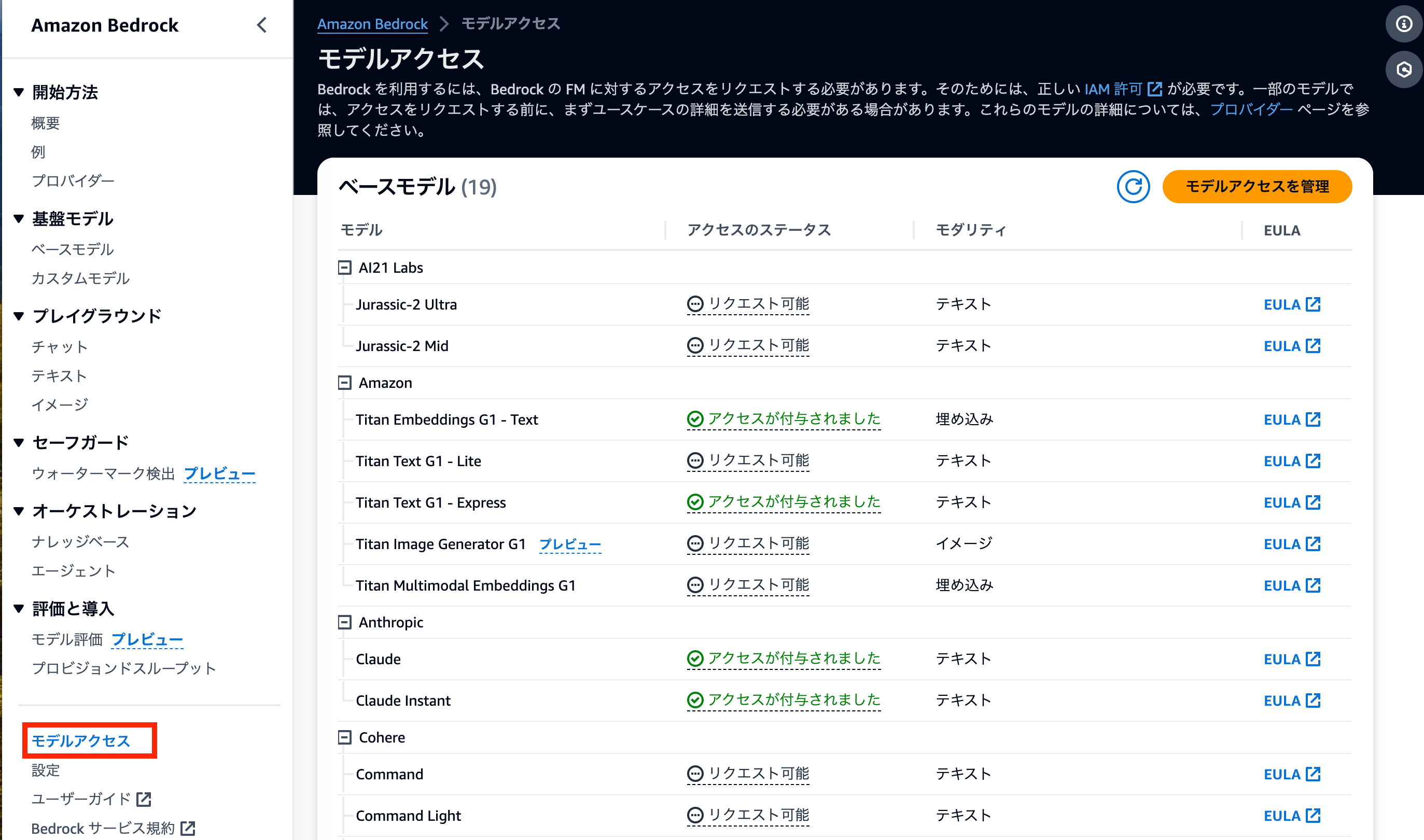
モデルのリクエストはリージョン事に行う必要があります。例えば、東京リージョンでモデルAをリクエストした後、バージニア北部リージョンでモデルAを使用したいとなった場合はバージニア北部リージョンで改めてモデルをリクエストする必要があります。
また、モデルによってはリクエストを行う際に簡単なアンケートに答える必要があります。
bedrockを試してみる
今回は以下の方法でテキスト生成を行う方法を説明します。
- boto3を使用する方法
- LangChainを使用する方法
事前準備
Docker Composeを利用してjupyter labの実行環境を作成し、そこで後述のソースコードを実行します。
├── Dockerfile
├── compose.yaml
├── entrypoint.sh
└── .env
各種ファイルの内容は以下のようになります。
これらのファイルの作成を終えたらdocker compose up -dを実行してjupyter labを起動します。
Dockerfile
下記以外に必要なライブラリは追加してください。
また、実行に必要なライブラリが足りない可能性がありますので予めご了承ください。
FROM python:3.9.18-bullseye
RUN apt-get upgrade && \
apt-get install unzip
# 使用しているCPUに応じてURLを変更する
RUN curl "https://awscli.amazonaws.com/awscli-exe-linux-aarch64.zip" -o "awscliv2.zip" && \
unzip awscliv2.zip && \
./aws/install
RUN python3 -m pip install --upgrade pip
RUN pip install jupyter-events \
jupyter-lsp \
jupyter-server-mathjax \
jupyter_client \
jupyter_core \
jupyter_server \
jupyter_server_terminals \
jupyterlab \
jupyterlab-widgets \
jupyterlab_code_formatter \
jupyterlab_git \
jupyterlab_pygments \
jupyterlab_server
COPY .env .env
COPY entrypoint.sh entrypoint.sh
RUN chmod +x entrypoint.sh
CMD ["/bin/bash","-c","./entrypoint.sh" ]
entrypoint.sh
AWS Cliで使用するアクセスキーやシークレットキーを.envファイルから読み込み設定しています。
設定後、jupyter labを起動します。
#!/bin/bash
source ".env"
aws configure set aws_access_key_id "${AWS_ACCESS_KEY_ID}" --profile "${AWS_PROFILE}" && \
aws configure set aws_secret_access_key "${AWS_SECRET_ACCESS_KEY}" --profile "${AWS_PROFILE}" && \
aws configure set region "${AWS_DEFAULT_REGION}" --profile "${AWS_PROFILE}" && \
aws configure set output "json" --profile "${AWS_PROFILE}"
jupyter-lab \
--allow-root \
--ip=0.0.0.0 \
--port=8888 \
--no-browser \
--NotebookApp.token='' \
--notebook-dir=/workspace
.env
AWSの環境情報をキーバリュー形式で記載します。
アクセスキーやシークレットキーは機微な情報に当たるためgitなどで管理する場合は注意してください。
AWS_ACCESS_KEY_ID='`XXXXXXXXXXXXXXXX'
AWS_SECRET_ACCESS_KEY='XXXXXXXXXXXXXXXXXXXXXXX'
AWS_DEFAULT_REGION='us-east-1'
AWS_PROFILE='xxxxxxx'
compose.yml
version: "3"
services:
jupyterlab:
build:
context: .
dockerfile: Dockerfile
restart: always
expose:
- "8888"
ports:
- "8888:8888"
volumes:
- ./py3/root_jupyter:/root/.jupyter
- ./amazon-bedrock-workshop:/workspace
boto3を使用してテキスト生成を実行する
以下はpythonのソースコードになります。
boto3のboto3_bedrock.invoke_modelを使用してテキスト生成を実行します。
FMとしてamazon.titan-tg1-largeを使用しています。
モデルによってbodyのパラメーターが異なります。bedrockのユーザーガイドをもとに使用するモデルに応じて変更してください。
import json
import os
import sys
import boto3
import botocore
from utils import bedrock, print_ww
boto3_bedrock = bedrock.get_bedrock_client(
assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None),
region=os.environ.get("AWS_DEFAULT_REGION", None)
)
prompt_data = """
私は工場で製品の品質管理を担当しています。取引先に不良品を送ってしまいました。
日本語で謝罪のメールを書いてください。
"""
body = json.dumps({
"inputText": prompt_data,
"textGenerationConfig":{
"maxTokenCount":4096,
"stopSequences":[],
"temperature":0,
"topP":0.9
}
})
response = boto3_bedrock.invoke_model(
body=body,
modelId='amazon.titan-tg1-large',
accept='application/json',
contentType='application/json'
)
response_body = json.loads(response.get('body').read())
print(response_body)
テキスト生成結果は以下のようになります。
{
'inputTextTokenCount': 105,
'results': [
{
'tokenCount': 390,
'outputText': '件名:不良品のお詫び\n\n株式会社○○\n○○部\u3000○○様\n\nお世話になっております。\n株式会社□□の△△です。\n\n本日、ご案内いただいた商品につきまして、不良品が発覚しました。\n\nこの度は、お客様にご迷惑をおかけしたことを深くお詫び申し上げます。\n\n不良品につきましては、突然発生した事態であり、原因は調査中です。\n\n今後は、同様の事態が再発しないよう、品質管理体制を強化し、更なる品質向上を図ります。\n\n今後とも、どうぞよろしくお願い申し上げます。\n\n署名',
'completionReason': 'FINISH'
}
]
}
LangChainを使用してテキスト生成を実行する
LangChainはLLMを使用したアプリケーションを開発するためのフレームワークとなります。
Bedrockだけでなく、OpenAIなどの複数のLLMで使用することができます。
また、LangChainを使用することで複雑なユースケースにも対応することができます。
今回はお客様からのフィードバックを下にLLMを使用して返答を生成する方法を紹介します。
また、問い合わせが多い場合を想定して顧客の名前、フィードバックの内容、及び問い合わせの受付者は変数として定義し、それ以外のプロンプトは使い回せるようにします。
ソースコードは以下のようになります。今回はFMとしてanthropic.claude-v2を使用します。
import json
import os
import sys
import boto3
module_path = "."
sys.path.append(os.path.abspath(module_path))
from utils import bedrock, print_ww
from langchain.lms.bedrock import Bedrock
from langchain.prompts import PromptTemplate
boto3_bedrock = bedrock.get_bedrock_client(
assumed_role=os.environ.get("BEDROCK_ASSUME_ROLE", None),
region=os.environ.get("AWS_DEFAULT_REGION", None)
)
inference_modifier = {
'max_tokens_to_sample':4096,
"temperature":0.5,
"top_k":250,
"top_p":1,
"stop_sequences": ["\n\nHuman"]
}
textgen_lm = Bedrock(
model_id = "anthropic.claude-v2",
client = boto3_bedrock,
model_kwargs = inference_modifier
)
multi_var_prompt = PromptTemplate(
input_variables=[
"customerServiceManager",
"customerName",
"feedbackFromCustomer"
],
template="""
Human: お客様から頂いたフィードバックを下にサービスマネージャーである
{customerServiceManager}から{customerName}宛の謝罪のメールを書いてください。
<customer_feedback>
{feedbackFromCustomer}
</customer_feedback>
Assistant:"""
)
prompt = multi_var_prompt.format(
customerServiceManager="フリーレン",
customerName="アウラ",
feedbackFromCustomer="""
カスタマーサービスに電話したとき対応が非常に悪かったです。
3日後に電話するといったのに電話がありませんでした。
"""
)
response = textgen_lm(prompt)
email = response[response.index('\n')+1:]
テキスト生成結果は以下のようになります。
この度は弊社のカスタマーサービスにご不満をお持ちいただき、誠に申し訳ございませ
ん。
お客様からいただいたご意見を真摯に受け止め、サービスの改善に努めてまいります。
3日後にご連絡するとお約束したにも関わらず、その約束を守れなかったことを深くお詫び
申し上げます。お客様にご迷惑をおかけしたことを重く受け止めております。
今後このようなことがないよう、社内のプロセスを見直し、お客様とのコミュニケーショ
ンをより確実にするための対策を講じてまいります。
お客様には大変ご不便をおかけしてしまったことを心よりお詫び申し上げます。今後とも変
わらぬご愛顧を賜りますよう、よろしくお願い申し上げます。
フリーレン
サービスマネージャー
まとめ
bedrockを使用してテキスト生成を実行する方法を紹介しました。
同じようなテキストを生成する場合はLangChainを使用することで効率的にできることがわかりました。
時間があればbedrockについて別の記事を作成したいと思います。
- 閲覧数 320

コメントを追加